AI 的「聪明」和人类的「聪明」不是同一种东西——弄不清这一点,就会要么高估它,要么低估它。
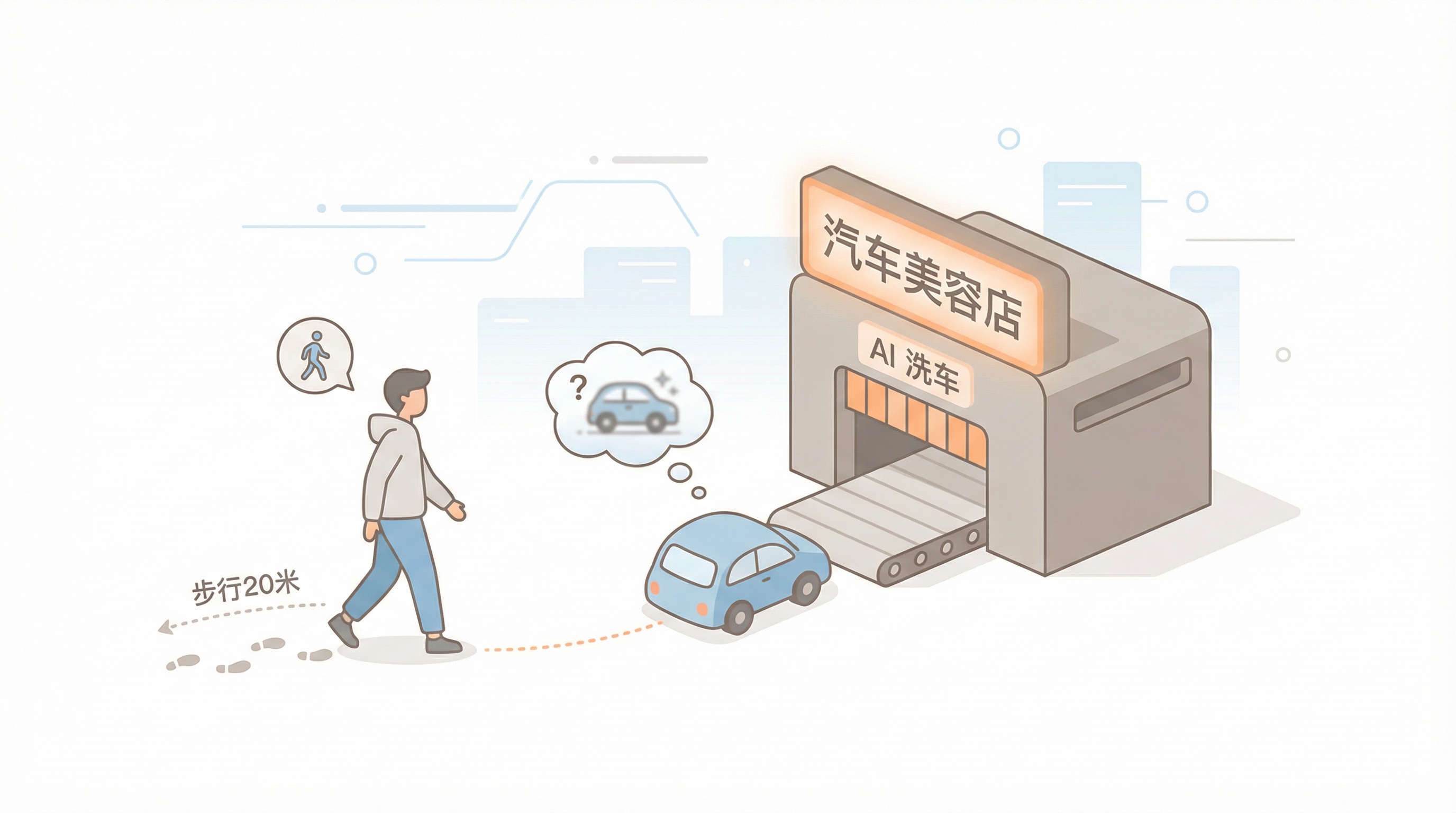
最近有个问题在网络上很火:「我要去小区旁 20 米的洗车店洗车,请问步行还是开车?」不少 AI 会认真建议你:20 米很近,步行环保又锻炼身体。你忍不住笑:不开车去,洗车店洗什么?洗我的腿吗?这类现象有个正式名字叫 AI 幻觉(AI Hallucination):模型用非常笃定的语气,给出逻辑上站不住脚或与事实不符的回答。
幻觉背后的原因,不只是「AI 还笨」或「数据不够」。实质是:今天的 AI 是在用「猜下一个字」的统计方式生成文字,它缺的是对物理世界和因果逻辑的「世界感」。理解这一点,才能说清为什么眼下它既不能当你的主治医师,也替代不了科学家和创意工作者;以及行业正在用哪些办法给这件事「打补丁」。
洗车悖论与 9.11 比 9.9 大:幻觉长什么样
「20 米洗车该步行还是开车」和另一道流传很广的题是同一类陷阱:「9.11 和 9.9 哪个大?」很多模型会答 9.11 更大——因为它把数字当成了软件版本号或日期(9 月 11 日),而不是在比较两个数的大小。两件事共同暴露的是:AI 会顺着训练数据里高概率出现的「搭配」往下说,而不是先想清楚这道题在问什么、需要什么前提。
在医学、法律、安全建议等场景里,这种「顺滑地跑偏」会带来真实风险。据学术与媒体报道,已有 AI 因训练数据中的统计偏差,对哮喘患者给出过「不需要特殊照顾」之类的建议;也有系统因为曾在某篇小说里读到某种蘑菇的描写,就敢回答「可以食用」。这些都不是个例,而是同一类问题的不同表现:模型在「像什么」的联想上很强,在「是什么」「该不该」的逻辑与事实上却不可靠。所以讨论幻觉,本质上是在讨论 AI 的能力边界——它擅长什么、不擅长什么,以及在哪些场景下必须由人做最后把关。2024 年能答对「9.11 与 9.9 哪个大」的模型还很少,到 2026 年这类题已常见于各大厂的基础评测;幻觉会随技术迭代减轻,但边界仍在。
它在「猜字」而不是推演,所以会掉进统计陷阱
要理解幻觉从哪来,得先搞清楚当前这类 AI 到底在干什么。
可以把大语言模型想成一台 「超级猜字机」:你输入一句话,它根据读过的海量文本,算出「下一个最可能出现的字(或词元)」是什么,然后一个接一个往下猜,拼成整段回答。它没有在内部先推演「洗车需要车」「所以必须开车去」——只是在无数网页、书籍、对话里,「20 米」和「步行」「短途」「环保」经常一起出现,所以概率一加权,它就顺着这条「统计捷径」滑过去了,忽略了「目的」是洗车、洗车必须有车这个常识。
「9.11 比 9.9 大」也是同一套逻辑的产物。在模型眼里,数字往往被拆成「词元」(Token)来处理,比如 9.11 可能被拆成「9」「.」「11」。在技术文档、版本说明里,「11」出现在「9」之后太常见了,所以它会答「9.11 更大」——模式识别压过了数学逻辑。一句话总结:AI 擅长的是「像什么」的联想,而不是「是什么」的严格推理。 这种差别,就是幻觉和逻辑失效的根源;不是它不想答对,而是它当前的运作方式本来就不是「先理解再作答」。
缺的不是知识量,而是「世界感」
人听到「去洗车」,脑子里会自动冒出画面:洗车店、水枪、泡沫、自己的车。这种对物理世界和日常流程的直觉,是我们在真实世界里摸爬滚打出来的。AI 没有身体,没摸过车,也没见过洗车房的水雾;它的「知识」全部来自文字。如果训练数据里没有反复、多角度地强调「洗车必须带车」,它就容易把这道题当成单纯的「距离题」:20 米 → 步行,完事。
有一句话概括得很准:今天的 AI 像一位背熟了百科全书却从没出过门的读书人——语义联想很强,常识推理却常常跟不上。就像没去过海边的人,再会形容也缺「那一口咸风」;AI 和世界的关系,跟我们不一样。所以问题不只是「少学了哪条知识」,而是它缺乏在真实世界中行动、观察、试错后沉淀下来的那种「世界模型」。这不是笨不笨的问题,而是它认识世界的方式和人类根本不同;补上这一点,是当前研究里最难、也最被重视的方向之一。
为什么今天的 AI 还替代不了医师、科学家和创意工作者
正因为 AI 是在「猜下一个字」、又缺「世界感」,在 医学诊断、法律判断、财务决策、人身安全 这类领域,它可能用非常笃定、专业的口吻,给出类似「步行去洗车」或「某种蘑菇可食用」那样离谱的建议。在这些场景里,错一次就可能付出健康或生命的代价,所以不能把 AI 当「正机长」,只能当「副驾」——可以参考、辅助,不能盲信、更不能替代最终责任主体。
科学家和创意工作者同样如此。科学研究依赖可重复的实验、严格的因果推断和「假设—验证—纠错」的闭环;AI 的统计联想既不能替你设计实验,也不能替代对「为什么」的严谨论证。创意工作则依赖真实的生活体验、情感与审美判断——这些恰恰是 AI 从文本里学不完整、甚至学歪的东西。所以 不是 AI 不够聪明,而是它解决「像什么」的能力很强,解决「是什么」「为什么」「该不该」的能力还远远不够。这些是当前技术必须面对、也在努力弥补的短板;未来它能不能真正替代这些角色,取决于幻觉与常识问题能不能被系统性地解决。
正因如此——问题出在模型质量与学习素材,而不是实验室的算力——每当有新模型或新工具问世,大家才会蜂拥而至,在赞叹「好神奇」的同时,依然由人类作为主力去挖掘它更大的魅力与边界。即便像 Clawbot 这类已具备一定「主动 AI」能力的形态已经出现,离真正的奇点仍远;在那之前,用好 AI 的关键仍然是:知道它擅长什么、会在哪里跑偏,然后由人来把关和延伸。
行业在如何打补丁:人类纠错、慢思考与查完再答
行业并没有坐等。目前有几类主流办法在一点一点把「常识」和「逻辑」补进去,用大白话说就是:
- 人类反馈强化学习(RLHF):用大量人类标注员给模型的回答打分、纠错,相当于不断告诉它「洗车要开车去」「这种蘑菇不能随便说可食用」;通过反复纠错,让模型逐渐靠近人类的判断标准。
- 思维链(Chain-of-Thought)与「慢思考」:让模型在给出最终答案前,先在内部一步步推演(例如「目标是洗车 → 洗车需要车 → 所以要开车」);像 OpenAI 的 o1、DeepSeek 的 R1 等,都在用这类「先想再答」的方式,减少一步到位的统计滑梯。
- 检索增强生成(RAG):在回答前先查权威资料或知识库,再根据查到的内容生成回答,避免纯靠「背下来的句子」瞎编。
这些手段都在生效。像「20 米洗车」和「9.11 vs 9.9」这类题,2024 年前后还能难倒一大批模型,今天已是常见基础测试;评测也在不断升级,会设计更复杂的复合逻辑题(例如「20 米长的加长悍马、洗车店离你只有 10 米,开车还是步行?」)来考察模型是否真的在推理。幻觉会随着技术和数据改进而减少,但不会一夜消失。
说到底,AI 可以是很好的创意副驾、学习助手、灵感来源,但在涉及健康、法律、金钱和人身安全时,别让它当正机长。今天的 AI 很强大,但强大建立在「统计与联想」之上,逻辑与常识的不足仍是结构性的。看清这一点,既能用好它,也能避免把不该交的责任交给它;未来它能不能真正替代医师、科学家或创意工作者,取决于这些幻觉与常识问题能不能被系统性地解决——而这件事正在被认真对待。
若想进一步了解「模型怎么工作」「人类反馈如何纠错」或「深度网络的设计逻辑」,可以读一读站内下面这几篇;都是面向读者写好的解读,不需要啃原始论文。
题图来源:见文首配图。
延伸阅读(站内)
- 【ChatGPT时刻10】InstructGPT与RLHF:对齐人类意图的关键技术 —— 文中提到的「人类反馈纠错」就是在用 RLHF;这篇讲清楚它是什么、怎么让模型更听人话。
- 【论文解读10】深度残差学习:ResNet解决网络退化问题 —— 从「信息怎么在深层网络里流动」理解为什么结构很重要;有助于理解「缺世界感」的模型为何容易跑偏。
- 【论文解读11】深度残差网络中的恒等映射:ResNet改进 —— 恒等映射与梯度流动,和「模型该在哪儿保留信息、在哪儿做计算」直接相关。
- 论文阅读开篇:Ilya 30u30 阅读计划 —— 想按主题系统补课(CNN、注意力、规模化和推理等),可以从这里的目录挑着读。