大模型时代喊的"开源",99% 不是你以为的那种开源。
当我们说 Linux 开源、Redis 开源的时候,意思很明确:把软件的"设计图纸"——源代码——全部公开,任何人都可以照着图纸把软件重新造一遍。这是软件的开源,公开图纸就等于公开一切。
但大模型的开源是一件根本不同的事。大模型的能力不在图纸里,而在一堆"经验"里——几千亿个数字,是用海量数据和巨额算力"喂"出来的,不是人一行一行写出来的。你可以公开这些数字,但别人拿到了也不知道你是怎么喂出来的。这是AI 的开源,它和软件开源之间的鸿沟,比大多数人意识到的要深得多。
深到什么程度?全球最权威的开源组织 OSI(开源促进会)在 2024 年 10 月专门发布了《开源 AI 定义 1.0》1,试图从头定义"AI 的开源到底应该是什么"——光是需要重新定义这件事本身,就说明传统软件开源的框架已经装不下大模型了。2026 年全国两会期间,中科院院士、阿里云创始人王坚更是直接呼吁:别再说"开源大模型"了,应该叫"开放权重模型"——因为你开放出去的不是一段代码,而是背后烧掉的电费和算力2。
这篇文章想做一件事:把大模型"开源"这个词拆开,一层一层看清楚里面到底装了什么。
大模型的"源代码"不是代码
软件开源的逻辑很简单:一个程序员写了一段代码,公开了,别人照着代码就能把同样的软件跑起来,还能改。代码就是全部,公开代码就是公开一切。
大模型完全不是这么回事。它的核心不是人写的代码,而是一种叫权重(weights)的东西——你可以把它理解成模型的"肌肉记忆"。就像一个厨师做了十年菜,他的手感、火候判断、调味直觉,全都长在身体里,不是写在菜谱上的。大模型的权重也一样:几十亿到几千亿个数字,是模型在海量数据上反复训练出来的结果。没有人能看懂这些数字具体是什么意思,但把它们加载到程序里,模型就能回答问题、写代码、做翻译。
关键区别在这里:公开厨师做好的菜,不等于公开他十年练出来的手艺。公开权重,不等于公开训练权重的方法。这就是 AI 开源和软件开源的根本区别。
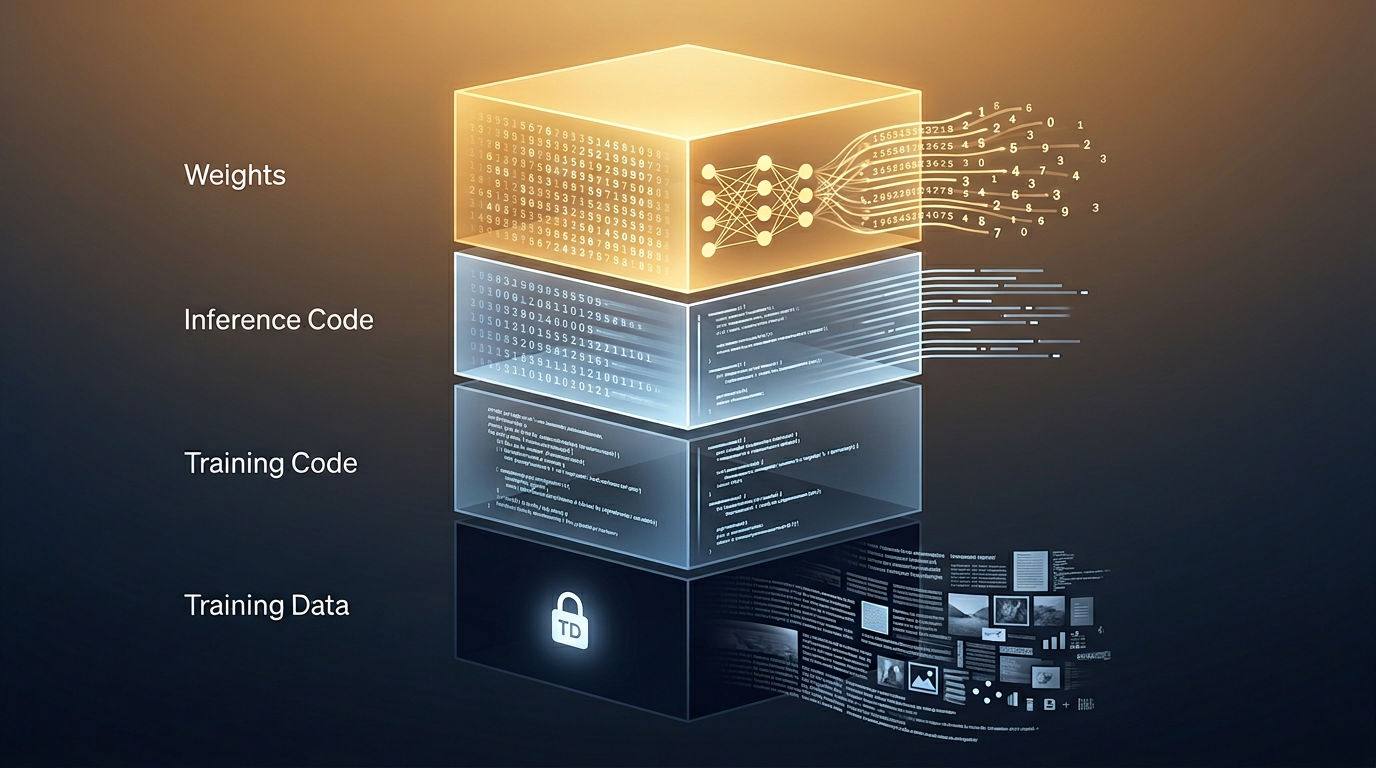
所以,大模型的世界里,“源代码"这个概念被拆成了至少四层:
| 层 | 是什么 | 厨师类比 |
|---|---|---|
| 权重 | 模型训练出来的"肌肉记忆” | 厨师十年练出来的手感和味觉直觉 |
| 推理代码 | 让模型跑起来的程序 | 把菜端上桌的流程 |
| 训练代码 | 从零训练模型的完整方法 | 厨师十年来的全部训练方法和食谱 |
| 训练数据 | 喂给模型学习的海量文本、图像等 | 厨师吃过的所有菜、看过的所有菜谱 |
传统软件开源,相当于把食谱和做法全部公开。大模型"开源",大多数时候只是把做好的菜端出来,告诉你怎么加热和摆盘。
三种"开源",差别巨大
明白了这四层之后,我们就可以看清楚:市面上号称"开源"的大模型,其实分成了截然不同的三种模式。
开放权重:给你成品,不给你生产车间
这是目前最主流的模式。Qwen、Llama 3、Gemma、Mistral——全球下载量最大的开源模型,几乎都属于这一类。
阿里的 Qwen(通义千问)是这个模式的典型代表。 你可以免费下载它全系列的模型——从轻量级的小模型到最新的 Qwen 3.5 旗舰版,附带使用说明和示例代码。你能拿它在自己的电脑或服务器上跑起来,用自己的数据做定制化训练(行话叫"微调"),甚至基于它做出更小的模型拿去商用。Qwen 的下载量已突破 7 亿次,全球开发者基于它做出的衍生模型超过 18 万个3——这个生态的繁荣,完全建立在"开放权重"这个模式之上。
但你拿不到的东西同样重要:Qwen 是怎么从零开始训练出来的?喂了什么数据?数据怎么筛选和清洗的?训练过程中几百个关键参数是怎么调的?模型怎么学会"像人一样说话"的?这些全都没有公开。你拿到了一个训练好的模型,但完全不知道它是怎么炼成的。
值得注意的是,即便同属"开放权重",“使用条款"之间的差异也不小。Qwen 用的是最宽松的 Apache 2.0 协议——随便用、随便改、随便商用,没有附加限制。Meta 的 Llama 3 则有门槛:如果你的产品月活用户超过 7 亿,需要单独找 Meta 谈授权。Google 的 Gemma 更严格:明确禁止你用它的模型去训练竞品。同样叫"开放权重”,你能拿它做什么,差别可以很大。
一句话:给你成品模型和使用手册,不给你生产车间的图纸。
代码+权重双开源:给你成品,也给你图纸
DeepSeek 走了一条不同的路。 它不仅开放了训练好的模型,还把"怎么训练的"也公开了——模型的架构设计、训练流程、核心算法优化,全部以最宽松的 MIT 协议放在了 GitHub 上。
这意味着什么?打个比方:Qwen 模式相当于给你一辆造好的车,你可以开、可以改装,但你不知道这辆车是怎么从零造出来的。DeepSeek 模式相当于不仅给你车,还给你整条生产线的图纸。我认识一个三人创业团队,他们拿到 DeepSeek 的训练代码后两周,就在自己的服务器上跑通了一个缩小版的训练流程——如果只有模型没有代码,他们顶多能给车换个轮毂;有了代码,他们可以造自己的车。全球数十个团队在几周内做出了类似的事情。
DeepSeek-V3 的训练成本约为 557.6 万美元4——这个数字之所以轰动,是因为 OpenAI 训练 GPT-4 花了大约 1 亿美元5,DeepSeek 用不到其十八分之一的钱,做出了接近的效果。但即便是 DeepSeek,也没有公开原始训练数据——也就是"喂"给模型学习的那些海量文本。这些数据涉及版权、隐私等法律问题,目前没有任何商业公司能完全公开训练数据而不面临法律风险。
一句话:给你成品模型、使用手册和生产车间的图纸,但原材料的配方还是保密的。
完全开源:连原材料都告诉你
这是最彻底的模式,也是最稀少的。艾伦人工智能研究院(AI2)的 OLMo 是目前最接近"完全开源"的大模型。 它公开了一切:训练代码、模型权重、训练数据(约 3 万亿条文本片段)、训练日志,甚至训练过程中的中间产物。换句话说,任何人都可以从零开始,用同样的材料和方法,把同一个模型重新训练一遍。在 OSI 对主流模型的评估中,OLMo 是少数真正达标的模型之一1。
按照 OSI 的标准,一个 AI 系统要被称为"开源",必须开放到让别人能从头复现的程度——数据、代码、模型参数,一个都不能少1。按照这个标准,目前市面上绝大多数号称"开源"的大模型,严格来说都不算开源——Llama、Qwen、Mixtral 统统没达标1。
这不是在苛责谁。OSI 的定义更像是一个理想标杆,而现实中的大模型开源是一个光谱——从完全封闭(GPT-4o、Claude)到开放权重(Qwen、Llama)到代码+权重双开源(DeepSeek)到接近完全开源(OLMo),每一步都在向更开放的方向移动,但每一步也都有自己的商业和法律约束。
当核心资产从代码变成权重,协作方式也变了
核心资产变了,围绕它的协作方式自然也跟着变了。传统软件开源的协作发生在 GitHub 上——大家一起改代码。但大模型时代,技术报告和 Hugging Face 这两样东西的重要性,已经超过了代码仓库本身。
为什么?因为当一个模型只开放权重的时候,代码仓库里其实没多少东西可看——主要就是使用说明和示例。那真正的技术含量去哪了?
去了技术报告里。你可以把技术报告理解成一篇详细的"造车说明书"——虽然不给你生产线,但告诉你这辆车的发动机是怎么设计的、为什么这么设计、和别的车比好在哪里。Qwen 的技术报告详细描述了模型怎么设计、怎么训练、效果怎么评测。DeepSeek-V3 的技术报告更是被全球研究者当教科书来读。Qwen 技术报告单篇被学术界引用超过 6000 次6,不是因为大家在引用它的代码,而是因为报告本身就是最重要的技术贡献。在传统软件世界里,代码自己会说话;但在大模型世界里,权重是一堆"看不懂的数字",技术报告成了唯一能让外界理解"这个模型为什么好"的窗口。
而模型本身的分享和协作,则发生在 Hugging Face 上——你可以把它理解成"大模型界的应用商店",只不过里面放的不是 App,而是模型。开发者在这里下载模型、上传自己定制化训练后的版本、分享压缩版本、讨论使用问题。Qwen 在 Hugging Face 上的下载量已突破 7 亿次,衍生模型超过 18 万个3。GitHub 是代码时代的协作基础设施,Hugging Face 是权重时代的协作基础设施。
为什么大多数公司只开放权重
理解了分层之后,一个自然的问题是:为什么不全部开放?
第一层是钱。 训练一个顶级大模型,算力成本动辄数千万美元。DeepSeek-V3 花了约 557.6 万美元4,已经是业界最省的了;OpenAI 训练 GPT-4 估计花了 1 亿美元5。完整公开训练代码和数据,等于把这笔巨额投资的核心产出免费送给竞争对手——哪家公司愿意?
第二层是官司。 这一层的压力可能比钱还大。大模型的训练数据从哪来?绝大部分是从互联网上抓取的——新闻、图片、书籍、论坛帖子,什么都有。这些内容的版权归谁?没人说得清。2023 年底,《纽约时报》直接把 OpenAI 和微软告上了法庭,说你们拿我几百万篇文章训练 AI 却不付钱,索赔数十亿美元7。图片库 Getty Images 也起诉了 Stability AI,说你们用了我 1200 万张图片训练 AI 画画8。在这种环境下,完全公开训练数据,几乎等于在法庭上主动提交证据。
第三层是核心竞争力。 训练代码里藏着一个团队最值钱的东西:怎么筛选和清洗数据、几百个关键参数怎么调、怎么让模型"学会说人话"。这些东西的价值,往往比训练出来的模型本身还大——因为模型是一次性的产出,而训练方法论是可以反复使用的能力。公开模型是请你吃饭,公开训练方法是把厨师的手艺教给你。
所以,开放权重是一个精心计算过的策略:它足以让开发者用你的模型做应用、建生态、扩大影响力,但不足以让竞争对手复制你的训练能力。
一张图看懂:谁开放了什么
| 模型 | 模型本身 | 使用代码 | 训练方法 | 训练数据 | 使用条款 | 模式 |
|---|---|---|---|---|---|---|
| GPT-4o / Claude | ❌ | ❌ | ❌ | ❌ | 闭源 | 完全封闭 |
| Qwen 3.5 | ✅ | ✅ | ❌ | ❌ | Apache 2.0 | 开放权重 |
| Llama 3 | ✅ | ✅ | ❌ | ❌ | Llama 社区协议 | 开放权重 |
| Gemma | ✅ | ✅ | ❌ | ❌ | Gemma 使用条款 | 开放权重 |
| Mistral | ✅ | ✅ | ❌ | ❌ | Apache 2.0 | 开放权重 |
| DeepSeek-V3 | ✅ | ✅ | ✅ | ❌ | MIT | 代码+权重双开源 |
| OLMo | ✅ | ✅ | ✅ | ✅ | Apache 2.0 | 接近完全开源 |
开放权重已经改变了整个生态
说到这里,可能有人会觉得:那这些模型不就是"假开源"吗?
2023 年 7 月之前,如果你想用一个能力接近 GPT-3.5 的模型,你只有一个选择:调用 OpenAI 的 API,按 token 付费,数据经过别人的服务器,没有任何定制空间。然后 Llama 2 来了。我记得一个做法律 AI 的朋友跟我说,他下载 Llama 2 权重的那天晚上几乎没睡——不是因为兴奋,而是因为他终于可以在自己的服务器上跑一个不错的模型,用自己的法律语料微调,不需要把客户的合同数据发送到 OpenAI 的服务器上。
Qwen 把这件事推得更远。全系列从 0.5B 到 72B 全部以 Apache 2.0 协议开放,意味着你可以拿它做任何事——商用、修改、再分发,没有附加限制。18 万个衍生模型、7 亿次下载3,这些数字背后是无数团队在 Qwen 的基础上构建自己的应用和服务。
开放权重不是传统意义上的"开源",但它创造了一个真实的、繁荣的、全球性的协作生态。这个生态的运作方式和传统开源不同——不是大家一起改代码,而是大家拿着同一个模型去做各自的定制和应用。但效果是一样的:降低门槛、促进创新、让更多人用上原本只有少数巨头才能提供的技术。
说到底,“开源"这个词在大模型时代被重新定义了。它不再是一个非黑即白的标签,而是一个从封闭到开放的连续光谱。在这个光谱上,每一步开放都有它的代价和收益,每一个选择都反映了技术理想和商业现实之间的博弈。与其纠结于"这算不算真正的开源”,不如问一个更实在的问题:它让多少人能用上原本用不上的技术?它让多少创新成为可能? 从这个角度看,即便是不完美的开放,也比完美的封闭要好得多。
- FIN -
参考
-
“The Open Source AI Definition - 1.0,” Open Source Initiative, 2024 年 10 月。链接 ↩︎ ↩︎ ↩︎ ↩︎
-
“阿里云创始人王坚:当前模型权重的开放本质上是数据资源和计算资源的开放,” 第一财经, 2026 年两会期间。链接 ↩︎
-
“Alibaba Qwen Model Downloads: Metrics and Enterprise Impact,” AI CERTs, 2026 年 1 月。截至 2026 年 1 月,Hugging Face 下载量达 7 亿次,社区衍生模型约 18 万个。链接 ↩︎ ↩︎ ↩︎
-
DeepSeek-V3 Technical Report, arXiv:2412.19437, 2024 年 12 月。训练成本约 557.6 万美元(2,788M H800 GPU 小时)。链接 ↩︎ ↩︎
-
“DeepSeek V3 and the cost of frontier AI models,” Interconnects, 2025。GPT-4 训练成本估计约 1 亿美元。链接 ↩︎ ↩︎
-
Bai, J. et al., “Qwen Technical Report,” arXiv:2309.16609, 2023。Google Scholar 引用数截至 2026 年 3 月约 6,300 次。链接 ↩︎
-
“The Times Sues OpenAI and Microsoft Over A.I. Use of Copyrighted Work,” The New York Times, 2023 年 12 月 27 日。链接 ↩︎
-
“Getty sues Stability AI for copying 12M photos,” Ars Technica, 2023 年 2 月。链接 ↩︎